Tensorflow 中的卷积神经网络 (CNN)
 2025年3月1日 23:24
2025年3月1日 23:24卷积神经网络 (CNN) 通过从图像中自动学习特征的空间层次结构,彻底改变了计算机视觉领域。在本文中,我们将探讨 CNN 的基本构建块,并向您展示如何使用 TensorFlow 实现 CNN 模型。
CNN 的构建块
CNN 由各层组成,每个层在处理和提取输入图像中的特征时执行特定任务。主要构建块是:

卷积神经网络架构
1. 卷积层
它接收一个输入特征图(可以是图像)并应用一组过滤器(或内核)来创建新的特征图。这些滤镜从图像中捕获不同的特征,例如边缘、角落和纹理。卷积作由滤波器大小、步幅和填充等参数控制。
import tensorflow as tf
conv_layer = tf.keras.layers.Conv2D(
filters=32, kernel_size=(3, 3), strides=(1, 1), padding='valid',
activation='relu', kernel_initializer='glorot_uniform',
)
2. 池化层
它用于对特征图进行下采样,即在保留最重要的信息的同时减小它们的大小。池化作有两种主要类型:
- Max Pooling:从特征图的区域获取最大值。
- Average Pooling:从特征图的区域中获取平均值。
import tensorflow as tf
max_pooling_layer = tf.keras.layers.MaxPool2D(
pool_size=(2, 2), strides=None, padding='valid', data_format=None
)
avg_pooling_layer = tf.keras.layers.AveragePooling2D(
pool_size=(2, 2), strides=None, padding='valid', data_format=None
)
注: 本文假定您正在处理图像数据(2D 数据)。如果您正在处理其他类型的数据,请参阅 TensorFlow API 了解特定维度选项。
3. 全连接层
它将上一层中的每个神经元连接到下一层中的每个神经元。它在 CNN 的最后层用于进行预测。它执行线性变换,后跟非线性激活函数。
import tensorflow as tf
fully_connected_layer = tf.keras.layers.Dense(
units=128, activation='relu', kernel_initializer='glorot_uniform',
)
TensorFlow 中的 CNN 实现
现在我们已经了解了构建块,让我们看看如何在 TensorFlow 中使用这些层实现 CNN 模型。我们将在 cifar 数据集上实现它。
1. 导入库
import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
2. 加载和预处理数据集
我们将使用 CIFAR-10 数据集。 它是一个流行的基准数据集,用于机器学习和计算机视觉任务,特别是用于图像分类。它包含 60,000 张 32×32 彩色图像,分为 10 个类,每个类 6,000 张图像。
- 归一化:图像中的像素值范围为 0 到 255。我们通过除以 255 来将图像缩放到 0 到 1 的范围来标准化图像。这有助于在训练期间实现模型收敛。
to_categorical()):将整数标签转换为独热编码格式,其中每个标签都表示为指示类的二进制向量。
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
train_images, test_images = train_images / 255.0, test_images / 255.0
train_labels = to_categorical(train_labels, 10)
test_labels = to_categorical(test_labels, 10)
3. 定义 CNN 模型
模型。Sequential():初始化层的线性堆栈,其中每个层只有一个输入和一个输出。Conv2D:添加一个具有 32 个过滤器的卷积层,每个过滤器的大小为 (3, 3)。MaxPool2D:添加最大池化层,以从上一个卷积层对特征图进行下采样。展平:将卷积层的输出展平为完全连接(密集)层所需的 1D 向量。密集:具有 128 个单元和 ReLU 激活的全连接层。
4. 编译模型
- Adam 优化器用于基于梯度的优化。它根据梯度的第一和第二矩调整学习率。
- 分类交叉熵用作多类分类问题的损失函数。
metrics=['accuracy']:指定我们希望在训练和评估期间跟踪准确性。
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
5. 训练模型
- 该模型将在整个数据集上训练 10 次迭代。
- 在更新权重之前,该模型将一次处理 64 张图像。
- 测试集用于在每个 epoch 之后进行验证,以跟踪模型在未见过的数据上的性能。
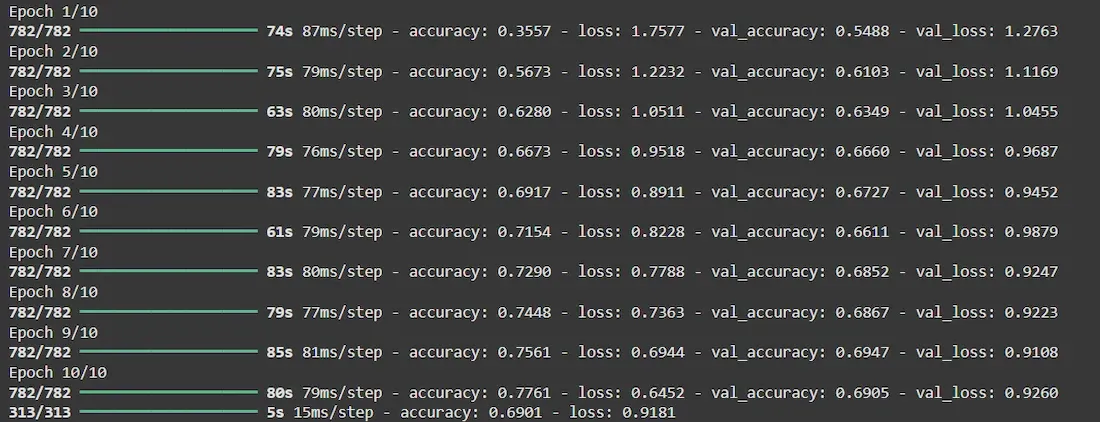
history = model.fit(train_images, train_labels, epochs=10, batch_size=64, validation_data=(test_images, test_labels))
输出:
6. Evaluating the Model
test_loss, test_acc = model.evaluate(test_images, test_labels)
print(f"Test accuracy: {test_acc * 100:.2f}%")
Output:
Test accuracy: 70.05%
测试准确率为 70%,这对于简单的 CNN 模型来说是很好的,我们可以根据我们的任务优化模型来进一步提高其准确率。
7. 绘制训练历史
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend(loc='upper right')
plt.show()
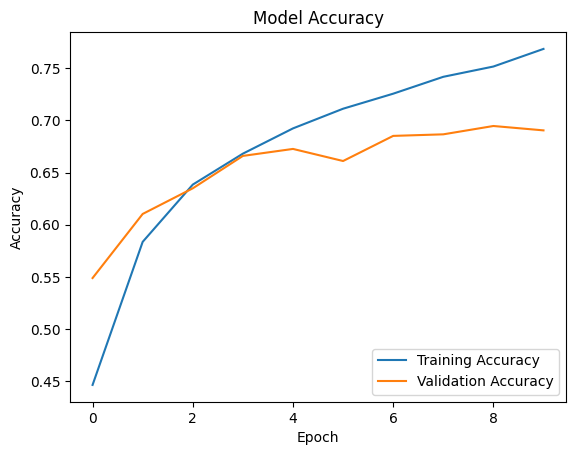
纪元与准确性
从图表中,我们可以观察到训练准确率稳步提高,这表明模型正在随着时间的推移而学习和改进。然而,验证准确性显示出一些波动,尤其是在稳定之前的早期 epoch 中。这表明该模型可以很好地泛化到看不见的验证数据,尽管仍有改进的余地,特别是在缩小训练和验证准确性之间的差距方面。





















工程师必备
- 项目客服
- 培训客服
- 平台客服
TOP




