技术分享︱突破大规模CFD仿真瓶颈:UNAP代数求解库性能实测与优化解析
 更新于2025年12月1日 14:58
更新于2025年12月1日 14:58
01 引言:CFD大规模仿真效率瓶颈
1.1 背景与目标
随着工业数值模拟在航空航天、能源、船舶及装备制造等领域的广泛应用,对计算流体力学(Computational Fluid Dynamics, CFD)软件的性能要求日益提升。某基于有限体积方法的通用 CFD 仿真软件,能够模拟稳态与瞬态下的复杂流动,并支持旋转机械流动分析与先进的共轭热传递(CHT)模型。结合特定的前处理器,该软件可以快速生成计算网格,从而为用户提供从前处理到数值求解的完整解决方案。
然而,随着工程问题规模的不断扩大,传统代数求解器在处理大规模稀疏线性方程组时暴露出性能瓶颈。具体而言,现有求解器在并行计算中的通信开销较大,尤其是代数多重网格(AMG)方法,难以充分发挥高性能计算平台的并行潜力,从而限制了整体计算效率和扩展性。
此次高性能改造的目标是对该CFD商软中的代数求解器进行替换与优化,开发出性能更高、并行效率更好的数值求解模块,以解决大规模并行通信开销过大的问题。通过此次改造,期望显著提升CFD软件在大规模计算场景下的计算速度与可扩展性,为复杂工程问题的高效仿真提供支持。
结合软件的主要使用场景,本次改造确定弱扩展性并行效率测试的环境为: 400万以上网格算例,以单核为基准计算10倍扩展时的并行效率。
1.2 高性能改造的必要性
在 CFD 数值求解过程中,代数求解器往往占据总计算时间的很大一部分,是影响整体性能的关键环节。当前求解器在单机计算中能够满足一定规模的计算需求,但在大规模算例的并行环境下,通信与同步开销逐渐成为性能瓶颈,尤其是在不可压流动压力方程的求解中,AMG作为经典的求解方法,存在着收敛性与并行效率之间的矛盾。这种性能限制不仅导致计算效率下降,还影响到软件在高性能平台上的可扩展性。
因此,有必要对代数求解器进行高性能改造,采用先进的并行求解方法与优化策略,以实现以下目标:
- 提高求解速度:通过优化算法和数据结构,减少单次迭代的计算与通信开销;
- 提升并行效率:增强在并行计算环境下的扩展性,充分利用多核和多节点计算资源;
- 增强工程适用性:支持更大规模、更复杂的工业仿真计算需求。
02 解析:AMGCL效率衰减实证
2.1 原始算法架构
最初阶段神工坊®技术团队采用了 AMGCL 作为代数求解库。AMGCL 是一个基于 C++ 的开源代数多重网格(Algebraic MultiGrid, AMG)求解器框架,具有模块化、可扩展和高性能的特点,广泛应用于大规模稀疏线性方程组的求解。
其基本架构可以分为以下几个层次:
- 前端接口层
提供用户友好的 API,用于构建稀疏矩阵、设置预条件子与迭代方法,并驱动求解流程。
- 预条件子模块
AMGCL 的核心在于代数多重网格预条件子构建。它通过稀疏矩阵自动生成层次化的粗网格与限制/延拓算子,从而加速 Krylov 子空间迭代方法的收敛。
- 迭代求解器模块
支持多种 Krylov 子空间方法,例如 CG、BiCGStab 等,通常与多重网格预条件子结合使用,以实现高效收敛。
- 后端执行层
提供多种计算后端以适配不同硬件环境,包括:
- CPU 并行后端(OpenMP、Threading Building Blocks 等)
- GPU 加速后端(CUDA、OpenCL 等)
- 分布式后端(MPI)
- 并行化与扩展性
AMGCL 通过模板化设计实现后端解耦,能够在不同硬件架构和规模下快速切换。并行化策略主要体现在粗网格构建与迭代求解阶段。
2.2 主要瓶颈分析
整体上,AMGCL 提供了一个相对成熟且易于使用的求解框架,为后续的高性能改造打下了基础。但在面对超大规模计算和高并行环境时,其在内存访问效率、通信开销等方面仍存在优化空间。
1. 计算性能瓶颈
尽管AMGCL中使用了许多OpenMP指令进行线程级别优化,但受稀疏矩阵迭代法核心计算特点限制,反而可能产生一些同步/规约开销,尤其是AMG方法中,图遍历 + 不规则访问 + 分支判断,OpenMP 细粒度任务化开销大。使得通过OpenMP使用多个CPU核心进行计算的收益没有那么明显。
2. 内存带宽瓶颈
稀疏线性方程组的求解并不是算法强度(浮点运算数/内存访问字节数)很高的运算,使得其主要瓶颈受限于访存效率而不是CPU的计算能力。以迭代法的核心操作:稀疏矩阵-向量乘(SpMV)为例,假设用CSR存储, 每个非零元需要:
- 读数值(8字节,double)
- 读列索引(4或8字节)
- 读对应的向量元素(8字节)
- 计算只涉及一个乘法 + 一个加法(2 FLOPs)
- 结果:每20-24 字节数据,只有2FLOPs → 算法强度 ≈ 0.1 FLOPs/Byte
根据Roofline Model,该强度较低,位于带宽瓶颈区域 Memory-Bound,内存带宽(斜率)决定了FLOPS上限。
此外,并行效率很容易受内存带宽瓶颈影响,在某个并行规模开始产生效率急剧下降的现象。下面通过测试进行验证:
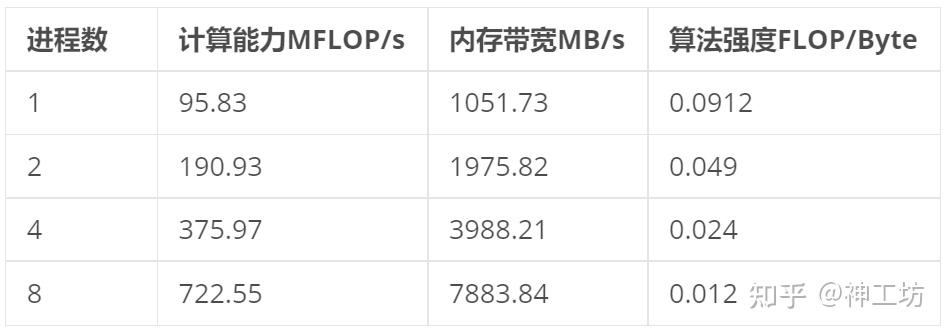
测试环境:12核CPU Intel® Xeon® Processor E5-2650 v4其 Roofline Model 图如下所示,可见其峰值性能约206.3GFLOPS,内存带宽约为29.4GB/s
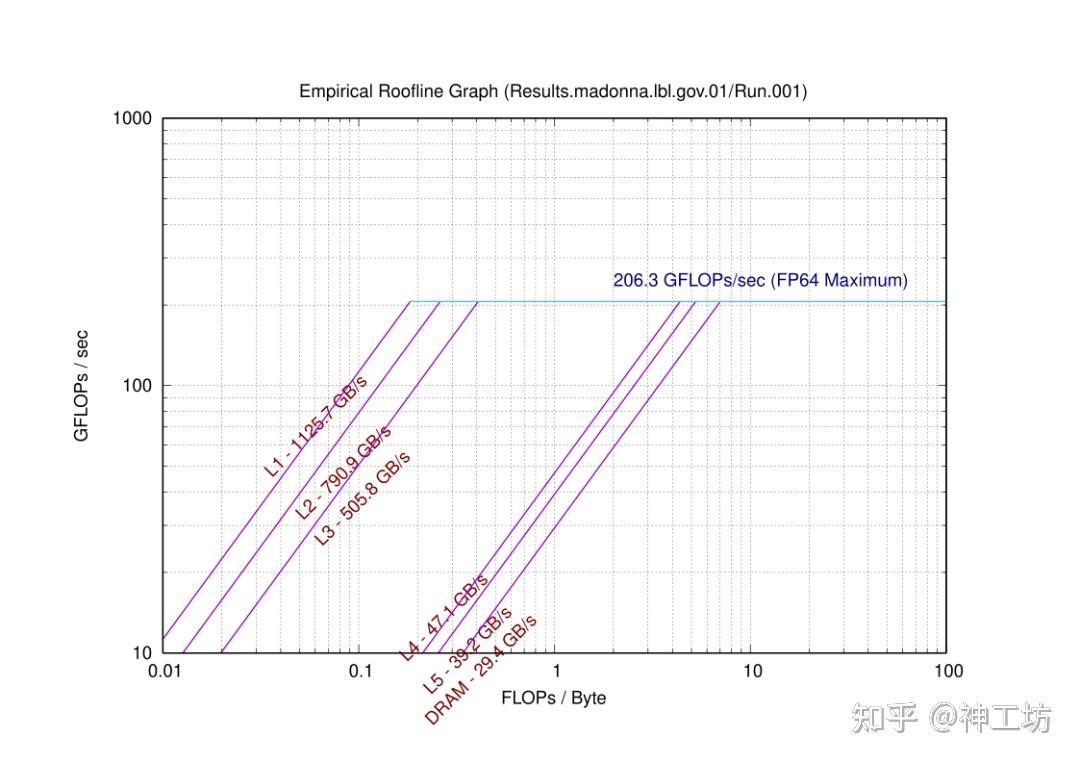
测试了400w网格压力方程使用AMGCL的AMG预条件+BiCGStab并行求解,发现10进程的并行效率仅35.83%。
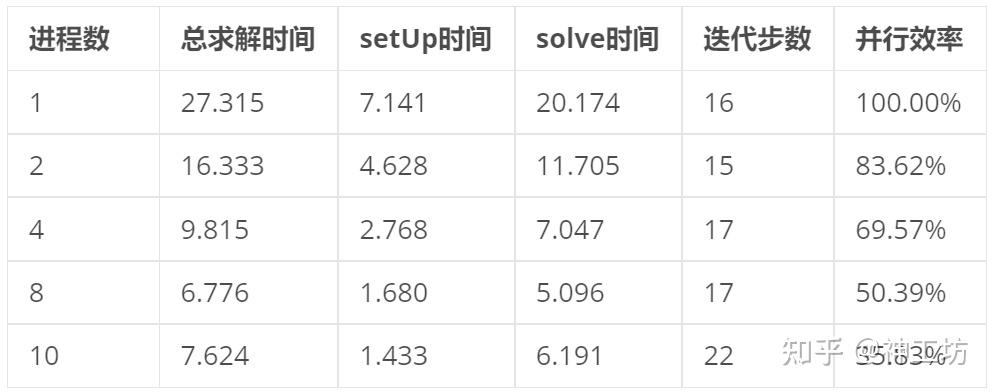
可以发现4进程开始并行效率下降十分迅速,分析其计算性能参数结果如下:
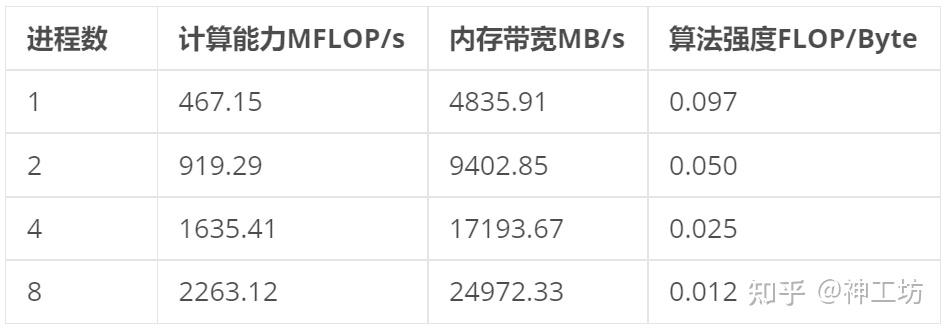
分析数据可以得出以下结论:
- 单核性能受限于内存带宽,单进程时算法强度仅 0.097 FLOP/Byte,远小于现代 CPU 的计算能力所需的平衡点,和上文对SpMV的算法强度分析结果一致;
- 随进程数增加,单核计算能力在下降:
- 从 1 到 2 核,MFLOP/s 从 467 提升到 919,几乎翻倍
- 到 4 核时 1635 MFLOP/s,约为单核的 3.5 倍
- 到 8 核时 2263 MFLOP/s,仅约为单核的 4.8 倍
- 内存带宽随并行数扩展而增长,但4进程开始出现倍数降低,说明共享内存总线成为瓶颈,出现多个进程同时争夺内存带宽。
3. 通信瓶颈
为了测试AMGCL的AMG方法通信瓶颈,需要了解其真实的并行效率。上节中使用Release版本的AMGCL测试发现并行效率受内存带宽的影响很大,为了避免该因素造成的干扰,我们使用Debug版本进行测试,其计算性能参数结果如下:
可见Debug版本计算能力随进程数增加接近线性提升,带宽利用率远低于Release版本,并行效率更多受MPI通信影响。
此时的400w网格压力方程使用AMGCL的AMG预条件+BiCGStab并行求解测试结果如下:
结果显示AMGCL以单核为基准计算10倍扩展时的并行效率为50%左右,通过Score-P等性能分析工具分析发现,其在AMG方法中的通信量极大,这和并行稀疏矩阵-矩阵乘(SpGEMM)的实现有关:
在并行环境中,通常需要通过MPI通信得到矩阵第行一整行的数据,且每个迭代步AMG方法都要重构一次,从而产生了大量的通信。
03 破局:UNAP三大优化策略
改造使用非结构代数求解库UNAP(UNstructured Algebra Package),它是一款最初面向异构平台的、采用 C++ 语言的轻量级代数求解库,目前支持申威众核异构平台和普通 x86 平台,支持Windows和Linux操作系统。
3.1 稀疏矩阵存储格式优化
UNAP的迭代求解部分采用LDU格式。LDU格式矩阵分为三个部分,上三角块,对角块和下三角块(如下图中所示),由于上三角块和下三角块的结构是对称的,因此可以共用同一套索引,如果以上三角块为基准,则在上三角块中的行标、列标刚好变成下三角块中的列标、行标,这样就只需要存储一半的拓扑数据。如果矩阵结构也是对称的,那么上、下三角的数据就可以只存一块。
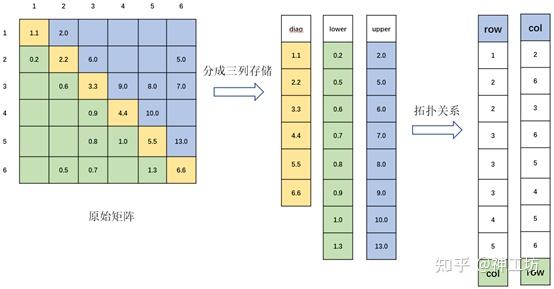
LDU矩阵中几个主要数组的说明如下:
- diag 、 lower 、 upper 存具体数值,说明如上图
- upperAddr : 存上三角列索引,相当于图中的 col
- lowerAddr : 存下三角列索引,相当于图中的 row
- 为了能让上下三角对应起来,unap的LDU格式要求数据按照一定的顺序排列,即上三角按行优先的顺序存储,下三角按列优先的顺序存储 ,上下三角(对角块)只储存列标(局部编号)。
- 进程边界部分(非对角块),按照对应进程号的不同分成了若干个部分,实际上可以说是COO格式,储存行标(局部编号)和列标(全局编号)。
3.2 迭代算法优化
3.3 代数多重网格方法优化
代数多重网格方法优化路线从以下三方面开展:
- 使用混合的聚集策略以在代价增长一定的前提下提升收敛的可控性与稳健性;
在细层基于强连接进行图聚集,得到聚集簇并构建延拓矩阵$P_t$,优化聚集过程以减少粗层矩阵通信界面大小;在粗层适当使用光滑聚集以提高收敛速度。
2. SpGEMM过程优化;
粗层矩阵通过$A_c=RAP$三重乘积构建,需要两次SpGEMM,其算法过程分为容量估计和数值写入两个阶段,同时需要整理对应行数据进行通信,可通过一定手段使用非阻塞通信将计算过程与之覆盖,减少实际耗时开销。
3. 重复使用结构信息的AMG;
稀疏矩阵的系数值是方程物理特性和几何信息的结合体,在系统矩阵$A$的稀疏模式不变的场景下,可以通过一定的聚集方法来构造可以重复使用的插值/限制算子($P_l$、$R_l$),从而避免每次都需要从零开始进行AMG的SetUp过程。也可以通过迭代数上限等阈值触发策略来控制重构插值/限制算子的时机。
04 验证:多平台实测性能对比
性能评估主要从两个方面进行:
- 特定CFD软件之外、矩阵单独求解效率对比;
- 特定CFD软件之中,整体求解情况对比;
4.1 测试环境与配置
- x86超算平台:CentOS7.9系统,64核CPU AMD EPYC 7H12 64-Core Processor
- Windows单机: Windows10系统,12核CPU(8个Performance-core) Intel® Core™ i7-13700F
4.2 性能测试方法
- 主要测试案例:CHT算例矩阵阶数为4254912、非零元个数27580140; AHM算例矩阵阶数为4639609、非零元个数31434615。
- 矩阵单独求解效率对比
- AMGCL: 使用gcc7.3.1+OpenMPI-4.1.0+cmake编译
- UNAP: 使用gcc7.3.1+OpenMPI-4.1.0+cmake编译
- 主要对比速度方程/压力方程的单次求解效率
- 整体求解情况对比
- AMGCL: 使用Windows单机默认编译环境编译
- UNAP:使用MSMPI+Visual Studio2019+cmake编译
- 对比所有方程的多次求解效率,迭代步数设为100
- 主要性能指标计算公式:
- 扩展性:强扩展性(Strong Scaling)和弱扩展性(Weak Scaling)是评估并行程序在不同并行资源(如处理器或节点)配置下性能表现的两种方法。
- 强扩展性是指在固定总工作量的情况下,通过增加处理器数量来减少任务完成时间的能力。具体来说,就是在处理器数量增加时,观察程序执行时间的变化情况。
- 弱扩展性是指在增加处理器数量的同时,也按比例增加问题规模,以考察程序在不同规模问题上的性能表现。通常,弱扩展性测试的目标是保持每个处理器的计算负载不变,观察程序的效率。
- 对于内存受限的程序,强扩展性测试需要特别注意内存带宽和容量的限制,常见的测试方式有:a. 在内存带宽不受限的平台上进行测试; b. 选择足够大的问题和并行规模,使得主要矛盾从内存带宽转移到通信、同步和负载均衡。
4.3 测试结果与分析
- 速度方程求解都采用: ILU(0)预条件+ BiCGStab
- 压力方程求解都采用: AMG预条件+ BiCGStab
- $Ax=b$求解结果均通过解向量的输出对比以保证正确性
1. x86超算平台
超算平台上测试不受内存带宽影响,并行效率仅受程序的通信、同步和负载均衡影响,其上限由代码的串行部分占比决定,能够真实的反映出程序的强扩展性。
(1)CHT算例
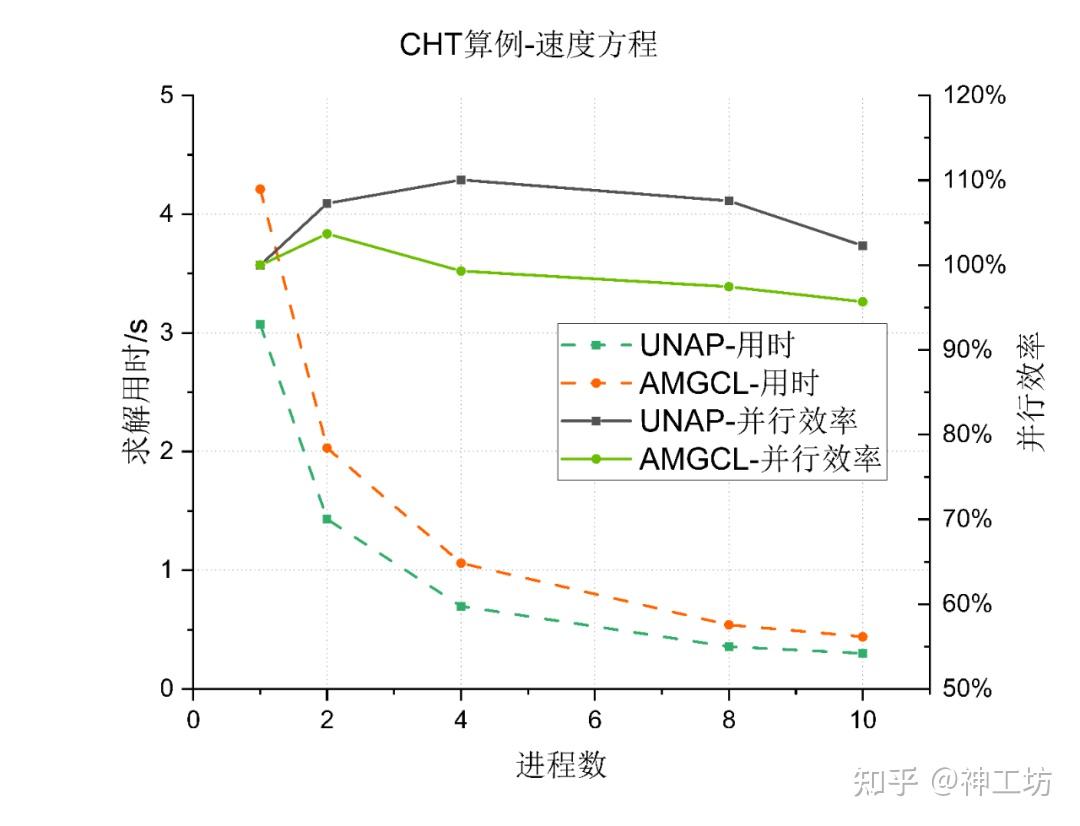
从 CHT 速度方程的求解结果来看,UNAP 在并行加速性能上优于 AMGCL。在进程数增加时,UNAP 不仅保持了较低的求解时间,而且在 2-8 进程范围内出现了超线性加速现象,并行效率一度超过 100%,说明其在缓存利用(cache命中率)和内存带宽利用(单位访存带宽能完成更多的浮点运算)方面具有优势。
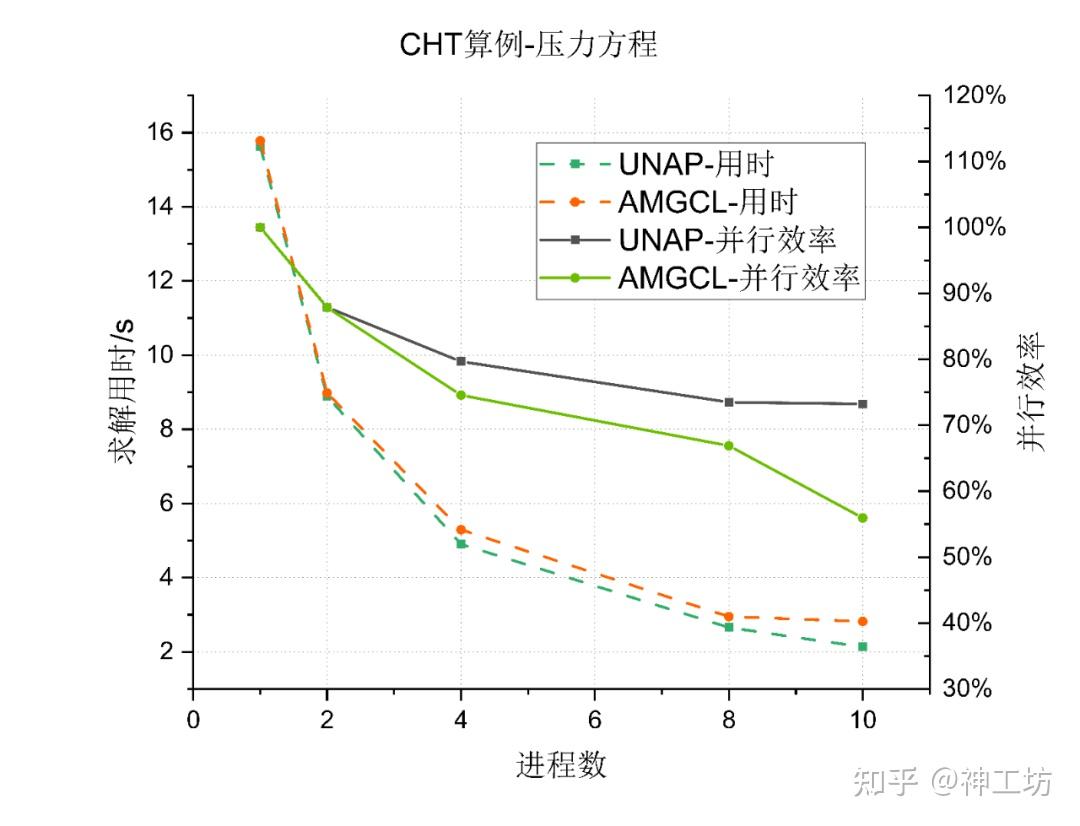
在压力方程的求解中,UNAP 与 AMGCL 在单进程下性能相近,随进程数增加两者用时均明显减少,UNAP曲线更偏下一些。在并行扩展性上,UNAP 的效率始终保持在较高水平,而 AMGCL 的效率则随规模增大快速下降,在大规模并行时仅为前者的约七成,10倍扩展并行效率为 56% ,不及UNAP的 73% ,显示出AMGCL在通信与负载均衡方面存在瓶颈更明显。
(2)AHM算例
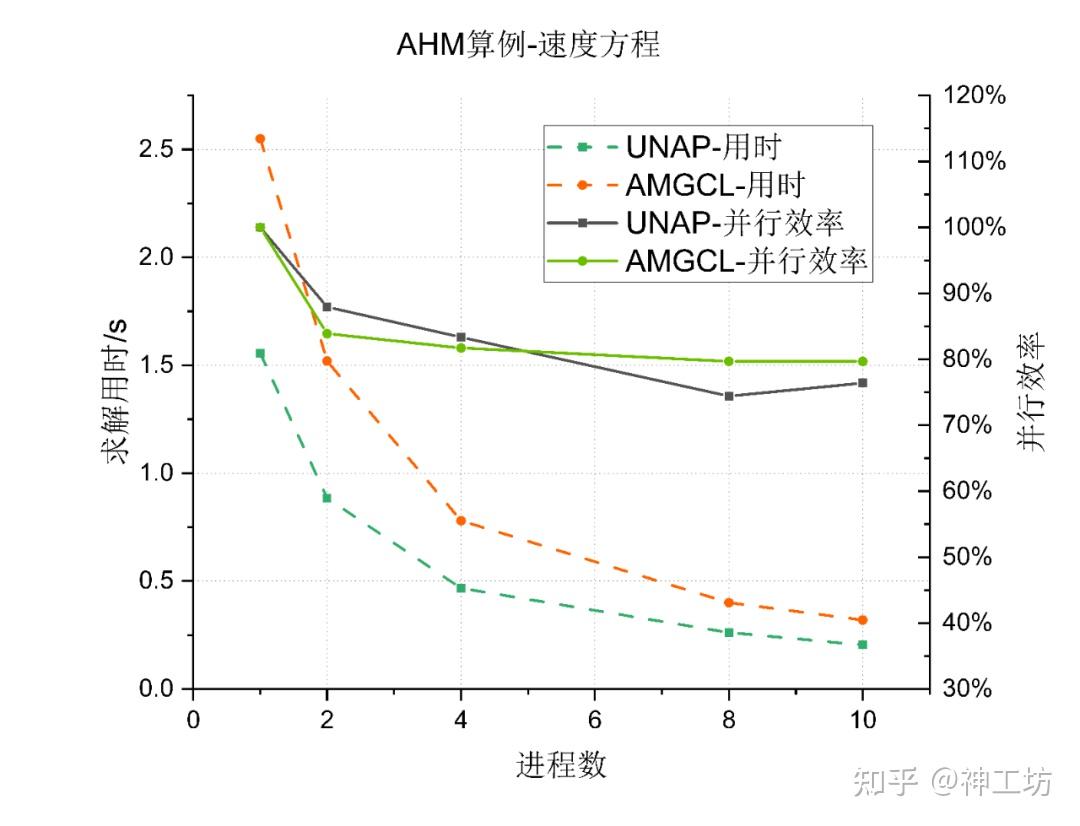
在 AHM 速度方程算例中,UNAP 在所有进程数下的求解用时均明显低于 AMGCL,体现出更优的单进程性能与整体效率;而在并行扩展性方面,两者表现接近,AMGCL 的并行效率略高于 UNAP,但并未以抵消其速度上的性能差距。
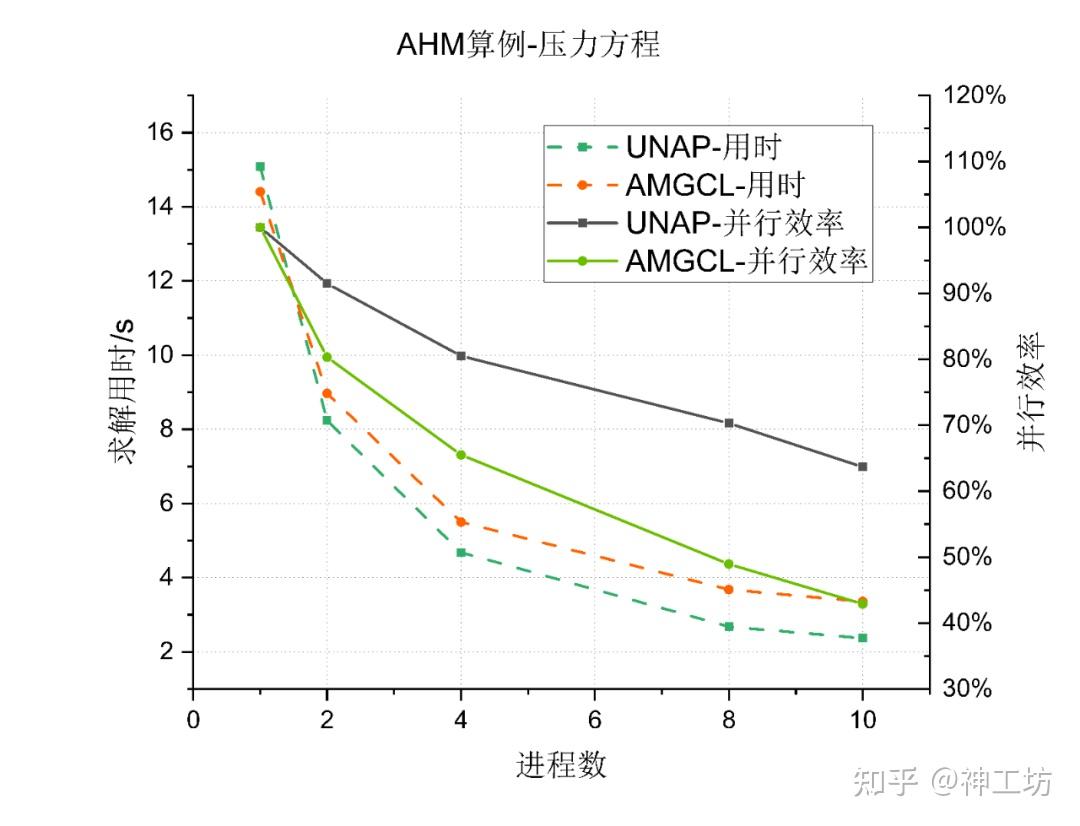
在AHM压力方程的求解中,UNAP 与 AMGCL 求解用时相近,串行时 AMGCL 略快,并行后 UNAP耗时更短; UNAP的并行效率始终在 AMGCL 的上方,10倍扩展并行效率为 63% 多,而 AMGCL 为 43% 。
2. Windows单机
(1)正确性验证
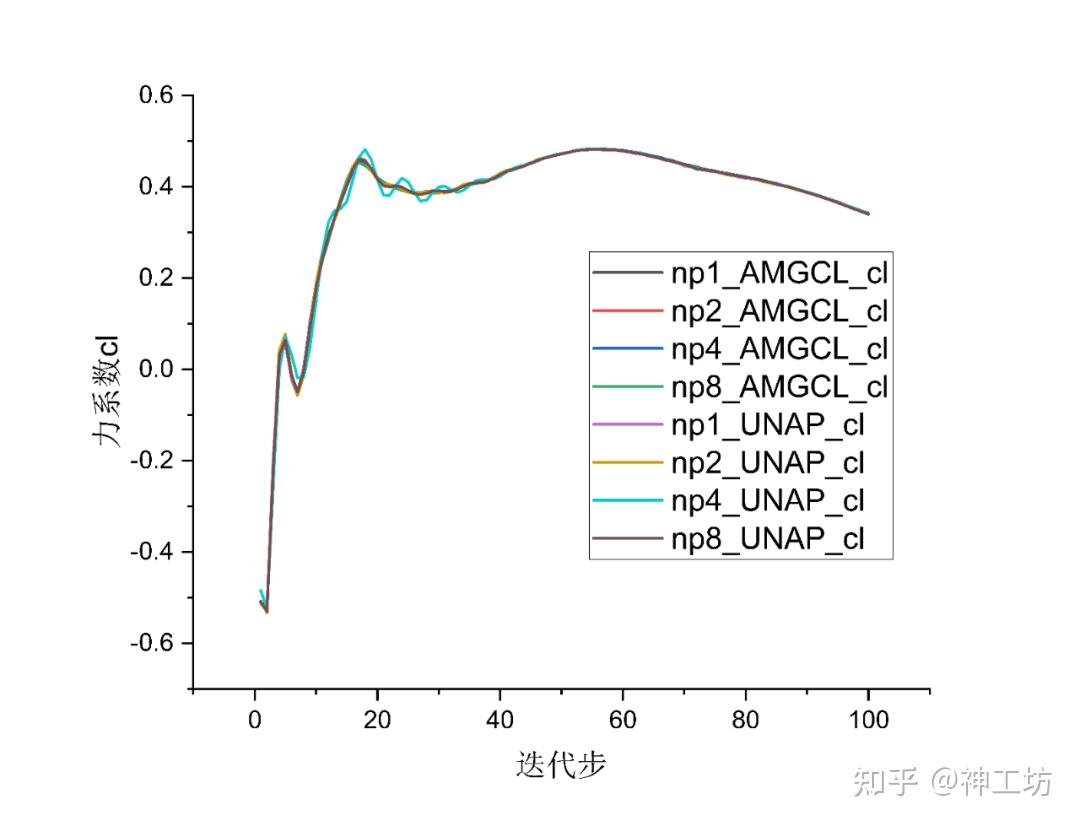
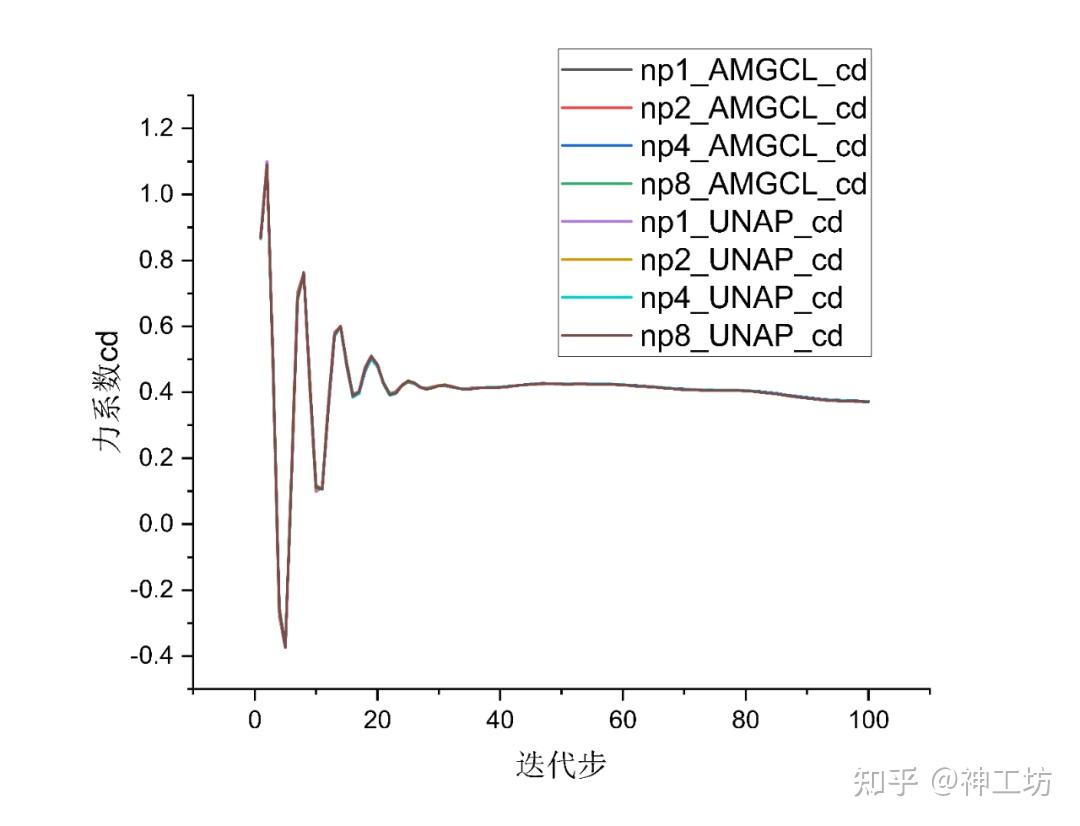
- AHM算例:通过对比100步迭代过程力系数的变化验证结果正确性
结果对比如下,可见当50步之后力系数逐渐趋于稳定后、不同进程数 AMGCL/UNAP并行计算得到的力系数值没有差别。
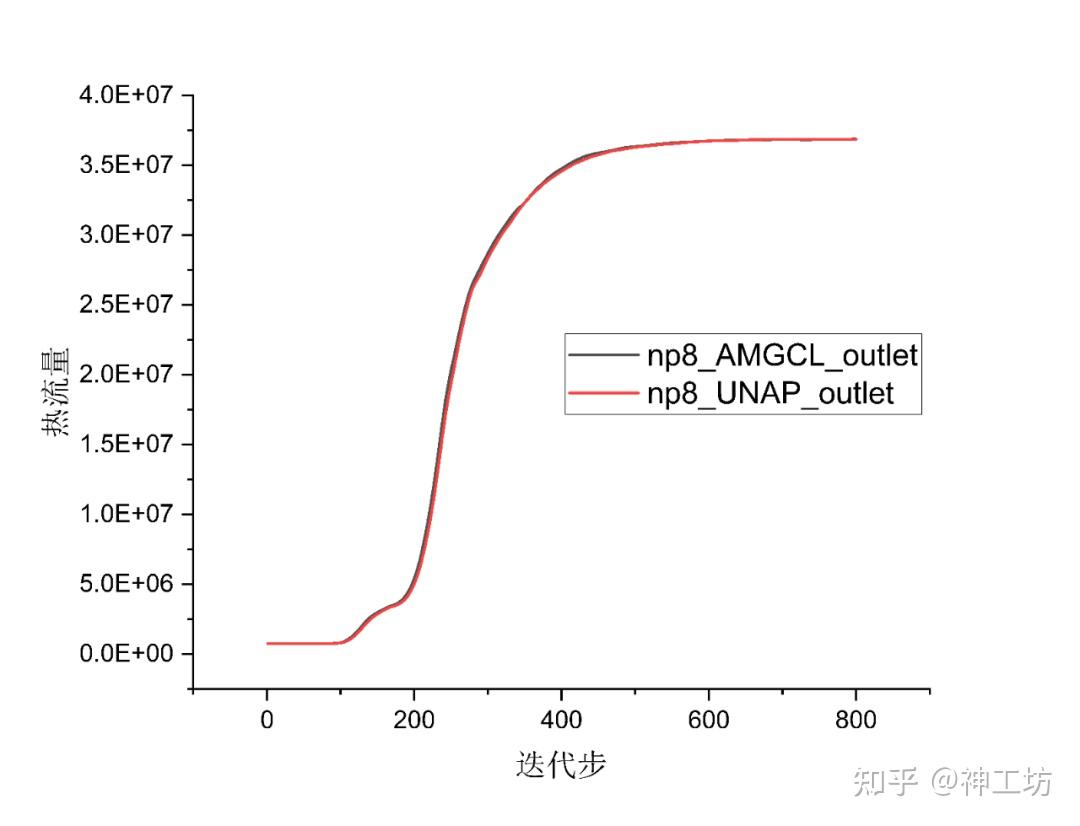
- CHT算例:通过对比800步迭代过程出口热流的变化验证结果正确性
结果对比如下图,可见AMGCL/UNAP并行计算得到的热流量变化曲线几乎没有差别。
该算例中线性方程组求解耗时统计如下:
AMGCL:
Max iluBiCGStab Time: 978.763s, count: 4800, average: 0.203909s Max amgCG Time: 976.65s, count: 813, average: 1.20129s
UNAP:
Max iluBiCGStab Time: 685.757s, count: 4800, average: 0.142866s Max amgCG Time: 616.886s, count: 813, average: 0.758777s
(2)CHT算例
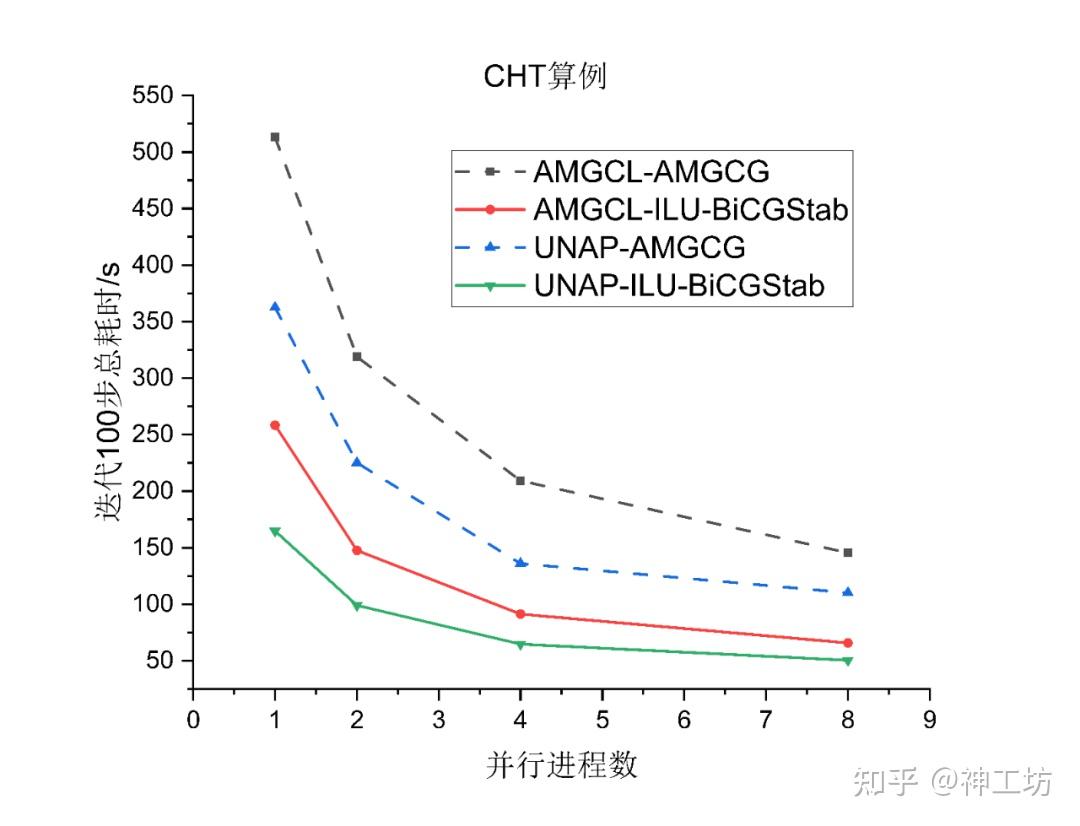
CHT算例测试结果如上图所示,可以发现ILU-BiCGStab方法UNAP始终在AMGCL曲线下方,串行时耗时减少35.3%,10进程并行时耗时减少27.8% 。同样AMGCG方法曲线UNAP始终在AMGCL下方,串行时耗时减少31.6%、10进程并行时耗时减少17.4% 。
(3)AHM算例
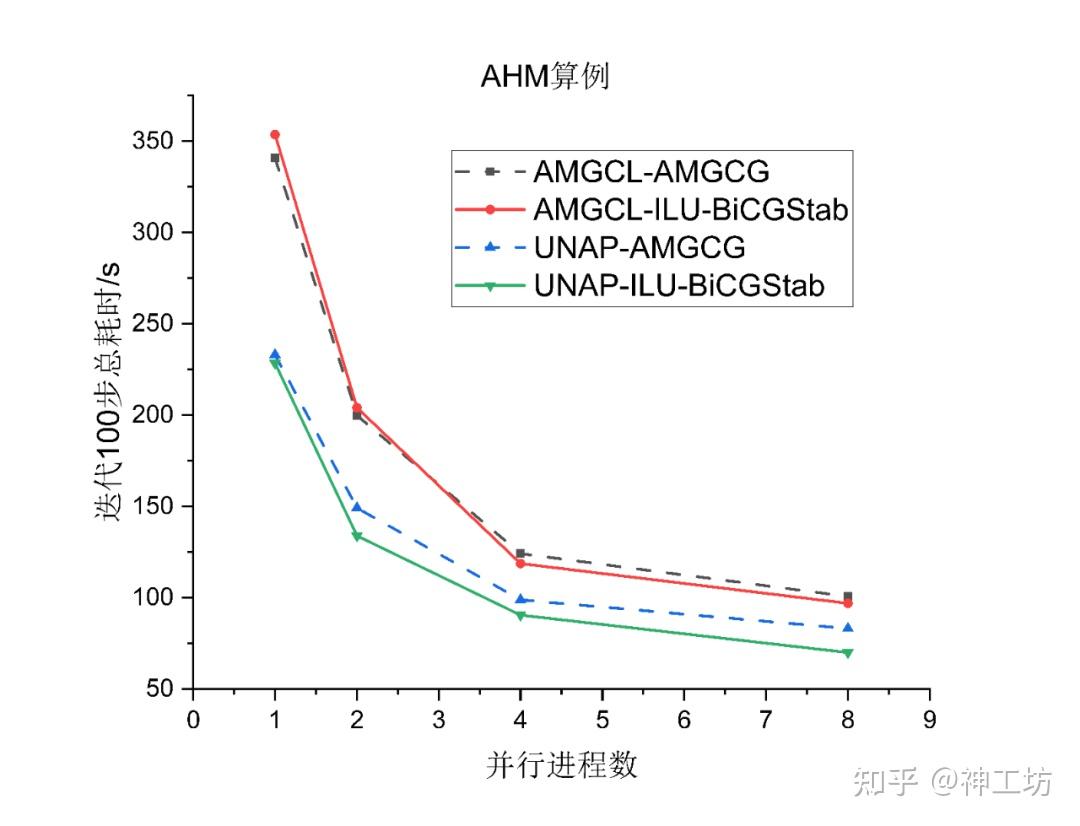
AHM算例测试结果如上图所示,可以发现ILU-BiCGStab方法UNAP始终在AMGCL曲线下方,串行时耗时减少36.2%,10进程并行时耗时减少23.2% 。同样AMGCG方法曲线UNAP始终在AMGCL下方, 串行时耗时减少29.3%、10进程并行时耗时减少24.3% 。
05 结语
5.1 成果总结:36%性能突破
神工坊®技术团队针对CFD商业软件在并行场景下代数求解器存在的性能瓶颈,开展了评估与高性能改造工作。通过替换 AMGCL 为 UNAP,并在稀疏矩阵存储格式、迭代算法及代数多重网格方法等方面开展优化,取得了以下主要成果:
1. 整体性能提升
在典型算例中,通过混合聚集策略、SpGEMM优化与重用AMG结构信息等方法,UNAP 相较原方法在单次迭代求解时间上实现了加速,100步迭代ILU-BiCGStab耗时减少23.2%-36.2%、AMG-CG减少17.4%-31.6%,提升了矩阵求解效率。
2. 并行效率改善
在 400 万以上网格的强扩展性测试中,UNAP 的AMG并行效率相比 AMGCL 明显提高,10 倍扩展规模下并行效率保持在60-70% 左右,验证了该方法在并行场景下的有效性。
3. 矩阵数据结构替换
LDU矩阵格式在减少存储与访存冗余的同时,提高了部分预条件子的应用效率;同时LDU格式与CFD软件内部的网格相关数据结构更加契合,为矩阵构建、组装等其他模块的进一步优化奠定了基础。
5.2 未来展望:迈向AI求解新阶段
本次高性能改造在提升CFD软件代数求解器的性能与并行效率方面取得了可观成效,未来神工坊®技术团队的研究与开发工作将主要在AI 驱动的代数求解加速方向攻坚克难。神工坊®将引入人工智能方法对代数求解过程进行智能化优化,包括:自动选择最优求解器与预条件子、智能调节参数、以及基于深度学习的迭代初值预测,以进一步提升收敛速度和鲁棒性。






















工程师必备
- 项目客服
- 培训客服
- 平台客服
TOP




