什么是大型语言模型 (LLM)?
 2025年1月4日 08:53
2025年1月4日 08:53
大型语言模型 (LLM) 代表了人工智能的突破,它采用具有广泛参数的神经网络技术进行高级语言处理。
本文探讨了 LLM 的演变、架构、应用和挑战,重点介绍了它们在自然语言处理 (NLP) 领域的影响。
什么是大型语言模型 (LLM)?
大型语言模型是一种人工智能算法,它应用具有大量参数的神经网络技术,使用自我监督学习技术来处理和理解人类语言或文本。文本生成、机器翻译、摘要编写、从文本生成图像、机器编码、聊天机器人或对话式 AI 等任务都是大型 Languag.e 模型的应用程序。此类 LLM 模型的示例包括 open AI 的 Chat GPT、Google 的 BERT(来自 Transformers 的双向编码器表示)等。
有许多技术被尝试执行与自然语言相关的任务,但 LLM 纯粹基于深度学习方法。LLM(大型语言模型)模型在捕获手头文本中的复杂实体关系方面非常有效,并且可以使用我们希望使用的特定语言的语义和句法生成文本。

使用 AI 创作生成的图像
LLM 模型
如果我们只谈论 GPT(生成式预训练转换器)模型中的进步规模,那么:
- GPT-1 于 2018 年发布,包含 1.17 亿个参数,9.85 亿个单词。
- GPT-2 于 2019 年发布,包含 15 亿个参数。
- GPT-3 于 2020 年发布,包含 1750 亿个参数。Chat GPT 也基于这个模型。
- GPT-4 模型预计将于 2023 年发布,并且可能包含数万亿个参数。
大型语言模型如何工作?
大型语言模型 (LLM) 基于深度学习的原理运行,利用神经网络架构来处理和理解人类语言。
这些模型使用自我监督学习技术在庞大的数据集上进行训练。他们功能的核心在于他们在训练期间从不同的语言数据中学习的复杂模式和关系。LLM 由多个层组成,包括前馈层、嵌入层和注意力层。他们使用注意力机制(如自我注意)来权衡序列中不同标记的重要性,从而使模型能够捕获依赖关系和关系。
LLM 的架构
大型语言模型 (LLM) 的架构由许多因素决定,例如特定模型设计的目标、可用的计算资源以及 LLM 要执行的语言处理任务的类型。LLM 的一般架构由许多层组成,例如前馈层、嵌入层、注意力层。嵌入其中的文本将协作在一起以生成预测。
影响大型语言模型架构的重要组成部分 –
- 模型大小和参数计数
- 输入表示
- 自我注意机制
- 培训目标
- 计算效率
- 解码和输出生成
基于 Transformer 的 LLM 模型架构
基于 Transformer 的模型彻底改变了自然语言处理任务,通常遵循包括以下组件的一般体系结构:
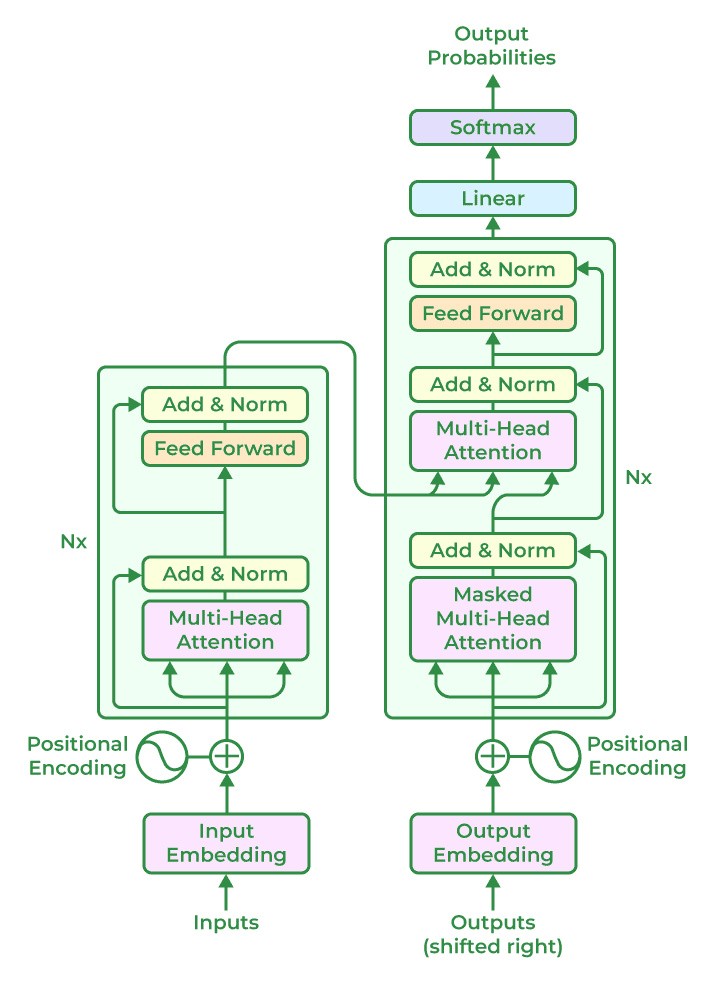
- 输入嵌入:输入文本被标记成更小的单元,例如单词或子单词,并且每个标记都嵌入到一个连续的向量表示中。此嵌入步骤捕获输入的语义和语法信息。
- 位置编码:位置编码被添加到输入嵌入中,以提供有关标记位置的信息,因为转换器不会自然地对标记的顺序进行编码。这使模型能够在考虑 Sequences 顺序的同时处理 Token。
- 编码器:编码器基于神经网络技术,分析输入文本并创建许多隐藏状态,以保护文本数据的上下文和含义。多个编码器层构成了 transformer 架构的核心。Self-attention 机制和前馈神经网络是每个编码器层的两个基本子组件。
- Self-Attention Mechanism:Self-attention 使模型能够通过计算注意力分数来权衡输入序列中不同标记的重要性。它允许模型以上下文感知的方式考虑不同标记之间的依赖关系和关系。
- 前馈神经网络:在自我注意步骤之后,前馈神经网络将独立应用于每个标记。该网络包括具有非线性激活函数的全连接层,允许模型捕获令牌之间的复杂交互。
- Decoder Layers:在一些基于 transformer 的模型中,除了编码器之外,还包括一个解码器组件。解码器层支持自回归生成,其中模型可以通过关注先前生成的标记来生成顺序输出。
- 多头注意力: 变形金刚通常采用多头注意力,其中自我注意与不同的习得注意力权重同时进行。这允许模型捕获不同类型的关系并同时处理 Importing 序列的各个部分。
- 层归一化:层归一化在 transformer 架构中的每个子组件或层之后应用。它有助于稳定学习过程并提高模型跨不同输入进行泛化的能力。
- 输出层:变压器模型的输出层可能因具体任务而异。例如,在语言建模中,通常使用线性投影后跟 SoftMax 激活来生成下一个标记的概率分布。
重要的是要记住,基于 transformer 的模型的实际架构可能会根据特定的研究和模型创建而改变和增强。为了实现不同的任务和目标,GPT、BERT 和 T5 等几种模型可能会集成更多组件或修改。
大型语言模型示例
现在让我们看看一些已经开发并可供推理的著名 LLM。
GPT – 3:GPT 的完整形式是生成式预训练的 Transformer,这是这种模型的第三个版本,因此编号为 3。这是由 Open AI 开发的,您一定听说过 Chat GPT,它由 Open AI 推出,只不过是 GPT-3 模型。
BERT – 其完整形式是 Bidirectional Encoder Representations from Transformers。这种大型语言模型由 Google 开发,通常用于与自然语言相关的各种任务。此外,它可用于为特定文本生成嵌入向量,可能是为了训练其他模型。
RoBERTa – 其完整形式是稳健优化的 BERT 预训练方法。在一系列提高 transformer 架构性能的尝试中,RoBERTa 是由 Facebook AI Research 开发的 BERT 模型的增强版。
BLOOM – 这是由不同组织和研究人员联合起来的第一个多语言 LLM,他们结合他们的专业知识开发了这个类似于 GPT-3 架构的模型。
要进一步探索这些模型,您可以单击特定模型以了解如何通过使用开源平台(如 Open AI 的 Hugging Face)来使用它们。这些文章涵盖了 Python 中每个模型的实现部分。
大型语言模型使用案例
对 LLM 如此热衷的主要原因是它们在可以完成的各种任务中的效率。从以上关于 LLM 的介绍和技术信息中,您一定已经了解了 Chat GPT 也是一款 LLM,因此,我们用它来描述大型语言模型的使用案例。
- 代码生成 – 这项服务最疯狂的使用案例之一是,它可以为用户向模型描述的特定任务生成相当准确的代码。
- 代码的调试和文档 – 如果您正在为有关如何调试它的一些代码而苦苦挣扎,那么 ChatGPT 是您的救星,因为它可以告诉您产生问题的代码行以及纠正问题的补救措施。此外,现在您不必花费数小时编写项目文档,您可以要求 为您完成此操作。
- 问题解答 – 正如您一定已经看到的那样,当 AI 驱动的个人助理发布时,人们过去常常向他们提出疯狂的问题,好吧,您也可以在这里与真正的问题一起这样做。
- 语言传输 – 它可以将一段文本从一种语言转换为另一种语言,因为它支持 50 多种母语。它还可以帮助您纠正内容中的语法错误。
LLM 的用例不仅限于上述,还必须具有足够的创造力来编写更好的提示,并且您可以让这些模型执行各种任务,因为它们经过训练,可以执行一次性学习和零次学习方法的任务。正因为如此,对于期待广泛使用 ChatGPT 类型模型的人来说,提示工程在学术界是一个全新的热门话题。
大型语言模型应用程序
LLM,例如 GPT-3,在各个领域都有广泛的应用。他们中的少数是:
自然语言理解 (NLU)
- 大型语言模型为能够进行自然对话的高级聊天机器人提供支持。
- 它们可用于为日程安排、提醒和信息检索等任务创建智能虚拟助手。
内容生成
- 为各种目的创建类似人类的文本,包括内容创建、创意写作和讲故事。
- 根据自然语言描述或命令编写代码片段。
语言翻译
大型语言模型可以帮助在不同语言之间翻译文本,提高准确性和流畅度。
文本摘要
生成较长文本或文章的简明摘要。
情感分析
分析和理解社交媒体帖子、评论和评论中表达的情绪。
NLP 和 LLM 之间的区别
NLP 是自然语言处理,是人工智能 (AI) 的一个领域。它包括算法的开发。NLP 是一个比 LLM 更广泛的领域,它由算法和技术组成。NLP 规定了两种方法,即机器学习和分析语言数据。NLP 的应用是 -
- 汽车常规任务
- 改进搜索
- 搜索引擎优化
- 分析和组织大型文档
- 社交媒体分析。
而另一方面,LLM 是一种大型语言模型,更特定于类人文本,提供内容生成和个性化推荐。
大型语言模型有哪些优势?
大型语言模型 (LLM) 具有多个优势,有助于它们在各种应用程序中得到广泛采用和成功:
- LLM 可以执行零样本学习,这意味着他们可以推广到他们没有明确训练的任务。此功能允许适应新的应用程序和场景,而无需额外的培训。
- LLM 可以有效地处理大量数据,使其适用于需要深入了解大量文本语料库的任务,例如语言翻译和文档摘要。
- LLM 可以 针对特定数据集或域进行微调,从而允许持续学习和适应特定的使用案例或行业。
- LLM 支持各种与语言相关的任务的自动化,从代码生成到内容创建,从而将人力资源释放到项目中更具战略性和更复杂的方面。
大型语言模型训练的挑战
LLM 在未来的能力是毋庸置疑的,这项技术是大多数人工智能应用程序的一部分,这些应用程序将由多个用户每天使用。但是 LLM 也有一些缺点。
- 要成功训练大型语言模型,需要数百万美元来建立可以利用并行性能训练模型的强大计算能力。
- 它需要数月的训练,然后人工在循环中对模型进行微调,以实现更好的性能。
- 需要大量文本语料库获取可能是一项具有挑战性的任务,因为 ChatGPT 仅被指控接受非法抓取的数据训练并构建用于商业目的的应用程序。
- 在全球变暖和气候变化的时代,我们不能忘记 LLM 的碳足迹,据说从头开始训练单个 AI 模型的碳足迹相当于五辆汽车一生的碳足迹,这是一个非常严重的问题。
结论
由于培训面临的挑战,LLM 迁移学习得到了大力推广,以消除上面讨论的所有挑战。LLM 有能力为 AI 驱动的应用程序带来革命,但该领域的进步似乎有点困难,因为仅仅增加模型的大小可能会提高其性能,但在特定时间之后,性能会达到饱和,处理这些模型的挑战将大于通过进一步增加模型大小所实现的性能提升。
常见问题解答
1. 什么是大型语言模型?
大型语言模型是一种强大的人工智能系统,经过大量文本数据的训练。
2.什么是 AI 中的 LLM?
在 AI 中,LLM 是指专为自然语言理解和生成而设计的大型语言模型,例如 GPT-3。
3. 什么是最好的大型语言模型?
打开 AI,ChatGPT,GPT-3,GooseAI,Claude,Cohere,GPT-4。
4. LLM 模型如何运作?
LLM 的工作原理是针对不同的语言数据、学习模式和关系进行训练,使他们能够理解和生成类似人类的文本。
5. 什么是 LLM 模型的示例?
GPT-3 (Generative Pre-trained Transformer 3) 是 AI 中最先进的大型语言模型的一个例子。
6. 什么是用于教育的大型语言模型?
大型语言模型被广泛用于教育目的:
- 提供学习目标
- 向学生提供任何主题的批判性总结
- 就学生想学习的任何主题进行教育。





















工程师必备
- 项目客服
- 培训客服
- 平台客服
TOP




