什么是神经网络?
 2024年10月19日 11:57
2024年10月19日 11:57
神经网络是模拟人脑复杂功能的计算模型。神经网络由互连的节点或神经元组成,它们处理数据并从中学习,从而支持机器学习中的模式识别和决策等任务。本文详细探讨了神经网络、神经网络的工作原理、架构等。
目录
- 神经网络的演变
- 什么是神经网络?
- 神经网络的工作原理是什么?
- 学习神经网络
- 神经网络的类型
- 神经网络的简单实现
神经网络的演变
自 1940 年代以来,神经网络领域取得了许多值得注意的进步:
- 1940 年代至 1950 年代:早期概念
- 神经网络始于 McCulloch 和 Pitts 引入第一个人工神经元数学模型。但计算限制使进展变得困难。
- 1960 年代至 1970 年代:感知器
- 这个时代由 Rosenblatt 在感知器方面的工作定义。 感知器是单层网络,其适用性仅限于可以单独线性解决的问题。
- 1980 年代:反向传播和联结主义
- Rumelhart、Hinton 和 Williams 发明的反向传播方法使多层网络训练成为可能。由于强调通过互连节点进行学习,联结主义获得了吸引力。
- 1990 年代:繁荣与寒冬
- 随着神经网络在图像识别、金融和其他领域的应用而蓬勃发展。然而,由于高昂的计算成本和夸大的期望,神经网络研究确实经历了一个“冬天”。
- 2000 年代:复兴和深度学习
- 更大的数据集、创新的结构和增强的处理能力刺激了它的卷土重来。 深度学习通过利用多个层,在许多学科中显示出惊人的效果。
- 2010 年代至今:深度学习占主导地位
- 卷积神经网络 (CNN) 和递归神经网络 (RNN) 这两种深度学习架构主导了机器学习。游戏、图片识别和自然语言处理方面的创新证明了他们的强大功能。
- 什么是神经网络?
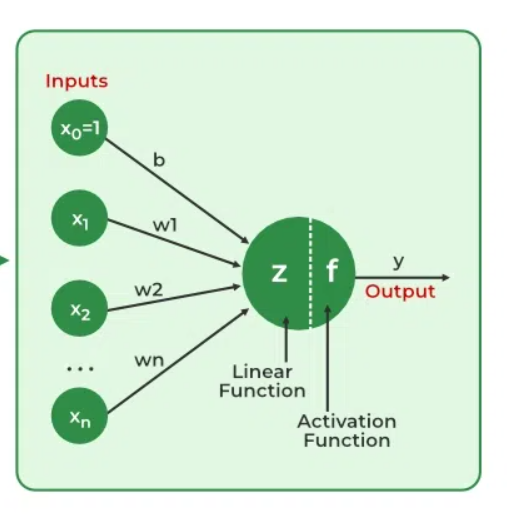
神经网络从数据中提取识别特征,缺乏预编程的理解。网络组件包括神经元、连接、权重、偏差、传播函数和学习规则。神经元接收由阈值和激活函数控制的输入。连接涉及调节信息传输的权重和偏差。学习、调整权重和偏差分为三个阶段:输入计算、输出生成和迭代优化,以提高网络对各种任务的熟练程度。
这些包括:
- 神经网络由新环境模拟。
- 然后,作为此模拟的结果,神经网络的自由参数会发生变化。
- 然后,由于神经网络的自由参数发生了变化,因此以新的方式响应环境。
神经网络的重要性
神经网络识别模式、解决复杂难题和适应不断变化的环境的能力至关重要。他们从数据中学习的能力具有深远的影响,从彻底改变自然语言处理和自动驾驶汽车等技术,到自动化决策流程和提高众多行业的效率。人工智能的发展在很大程度上依赖于神经网络,神经网络也驱动创新并影响技术的发展方向。
神经网络的工作原理是什么?
让我们通过一个神经网络工作原理的示例来了解:
考虑使用用于电子邮件分类的神经网络。输入层采用电子邮件内容、发件人信息和主题等功能。这些输入乘以调整后的权重,将穿过隐藏层。通过训练,该网络学会了识别指示电子邮件是否为垃圾邮件的模式。输出层具有二进制激活函数,可预测电子邮件是否为垃圾邮件 (1) 或非垃圾邮件 (0)。随着网络通过反向传播迭代优化其权重,它变得擅长区分垃圾邮件和合法电子邮件,展示了神经网络在电子邮件筛选等实际应用中的实用性。
神经网络的工作原理
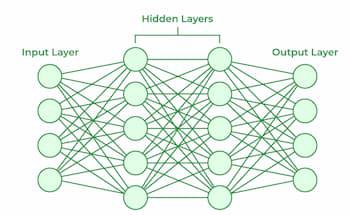
神经网络是模拟人脑功能某些特征的复杂系统。它由一个输入层、一个或多个隐藏层和一个由耦合的人工神经元层组成的输出层组成。基本过程的两个阶段称为反向传播前向传播。
前向传播
- Input Layer:输入层中的每个要素都由网络上的一个节点表示,该节点接收输入数据。
- 权重和连接:每个神经元连接的权重表示连接的强度。在整个训练过程中,这些权重会发生变化。
- 隐藏层:每个隐藏层神经元通过将输入乘以权重,将它们相加,然后通过激活函数传递它们来处理输入。通过这样做,引入了非线性,使网络能够识别复杂的模式。
- 输出:通过重复该过程直到到达输出层来产生最终结果。
反向传播
- 损失计算:根据实际目标值评估网络的输出,并使用损失函数计算差异。对于回归问题,均方误差(MSE) 通常用作成本函数。
- 损失功能:

 编辑
编辑- Gradient Descent:然后网络使用 Gradient Descent 来减少损失。为了降低不准确性,权重将根据损失相对于每个权重的导数进行更改。
- 调整权重:通过在整个网络中向后应用此迭代过程或反向传播,在每个连接处调整权重。
- 训练:在使用不同的数据样本进行训练时,前向传播、损失计算和反向传播的整个过程都是迭代完成的,使网络能够从数据中适应和学习模式。
- 驱动函数:模型非线性由修正线性单元 (ReLU) 或 sigmoid 等激活函数引入。他们决定是否 “触发” 神经元是基于整个加权输入。
学习神经网络
1. 通过监督学习学习
在监督式学习中,神经网络由可以访问两个输入-输出对的教师指导。网络根据输入创建输出,而不考虑周围环境。通过将这些输出与教师已知的所需输出进行比较,生成误差信号。为了减少错误,网络的参数会迭代更改,并在性能达到可接受水平时停止。
2. 通过无监督学习进行学习
无监督式学习中不存在等效输出变量。它的主要目标是理解传入数据的 (X) 底层结构。没有教练在场提供建议。相反,对数据模式和关系进行建模是预期的结果。回归和分类等词与监督学习有关,而无监督学习与聚类和关联有关。
3. 通过强化学习进行学习
通过与环境互动和以奖励或惩罚的形式提供反馈,网络获得了知识。找到一种随着时间的推移优化累积奖励的政策或策略是该网络的目标。这种经常用于游戏和决策应用程序。
神经网络的类型
可以使用七种类型的神经网络。
- 前馈神经网络:前馈神经网络是一种简单的人工神经网络架构,其中数据沿单个方向从输入移动到输出。它有 input、hidden 和 output 层;没有反馈循环。其简单的架构使其适用于许多应用程序,例如回归和模式识别。
- 多层感知器 (MLP):MLP 是一种具有三层或更多层的前馈神经网络,包括一个输入层、一个或多个隐藏层和一个输出层。它使用非线性激活函数。
- 卷积神经网络 (CNN):卷积神经网络 (CNN) 是一种专为图像处理而设计的专用人工神经网络。它采用卷积层从输入图像中自动学习分层特征,从而实现有效的图像识别和分类。CNN 彻底改变了计算机视觉,在对象检测和图像分析等任务中发挥着关键作用。
- 递归神经网络 (RNN):一种用于顺序数据处理的人工神经网络类型称为递归神经网络 (RNN)。它适用于上下文依赖关系至关重要的应用程序,例如时间序列预测和自然语言处理,因为它利用反馈循环,使信息能够在网络中生存。
- 长短期记忆 (LSTM):LSTM 是一种 RNN,旨在克服训练 RNN 中的梯度消失问题。它使用存储单元和门选择性地读取、写入和擦除信息。
神经网络的简单实现
代码案例
以下内容为付费内容,请购买后观看





















工程师必备
- 项目客服
- 培训客服
- 平台客服
TOP




