机器学习 |使用 Python 的多元线性回归
 2025年2月28日 21:27
2025年2月28日 21:27
线性回归是预测分析的基本常用方法。它是一种用于对因变量和一个自变量之间的关系进行建模的统计方法。 多元线性回归只是它的扩展版本。它尝试对两个或多个特征之间的关系进行建模,以拟合线性方程来预测一个因变量。
多元线性回归的步骤
执行多元线性回归的步骤几乎与简单线性回归的步骤相似 d不同 在评估中。我们可以使用它来找出哪个因素对预测输出的影响最大,以及不同的变量如何相互关联。
多元线性回归的方程为:
y=β0+β1X1+β2X2+⋯+βnXn
- y是因变量
- X1,X2,⋯XnX1,X2,⋯Xn是自变量
- β0β0是截距
- β1,β2,⋯βnβ1,β2,⋯βn是斜率
该算法的目标是找到可以根据自变量预测值的最佳拟合线方程。回归模型从数据集中学习一个函数(具有已知的 X 和 Y 值),并使用它来预测未知 X 的 Y 值。
使用虚拟变量处理分类数据
在多元回归模型中,我们经常会遇到分类数据,例如性别(男性/女性)、位置(城市/农村)等。由于回归模型通常需要数字输入,因此必须将分类数据转换为可用形式。
这就是 Dummy Variables 发挥作用的地方。虚拟变量是二进制变量(0 或 1),表示每个类别的存在或不存在。例如:
- 男性:如果男性为 1,否则为 0
- 女性:如果女性为 1,否则为 0
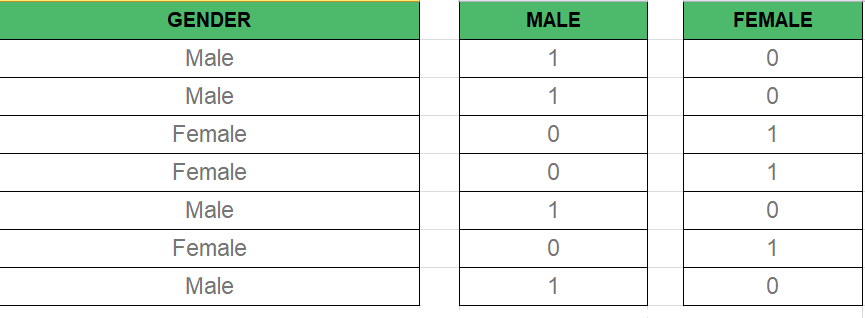
在多个类别的情况下(例如,颜色:“红色”、“蓝色”、“绿色”),我们为每个类别创建一个虚拟变量,排除一个以避免多重共线性(下面解释)。此过程称为 one-hot encoding,它将分类变量转换为适合回归模型的格式。
多元线性回归中的多重共线性
在构建多元线性回归模型时,可能会出现多重共线性。当两个或多个自变量彼此高度相关时,就会发生这种情况。这使得评估每个变量对因变量的单个贡献变得困难。
检测多重共线性包括两种技术:
- 相关矩阵:检查自变量之间的相关矩阵是检测多重共线性的常用方法。高相关性(接近 1 或 -1)表示潜在的多重共线性。
- VIF(方差膨胀因子):VIF 是一种度量,用于量化预测变量相关时估计回归系数的方差增加多少。高 VIF(通常高于 10)表明多重共线性。
在接下来的章节中,我们将深入学习这些技术
多元回归模型的假设
就像简单线性回归一样,我们在多元线性回归中也使用了一些假设:
- 线性度:因变量和自变量之间的关系应该是线性的。
- 同源性:误差的方差在所有自变量水平上应保持不变。
- 多元正态性:残差应服从正态分布。
- 无多重共线性:自变量不应高度相关。
在 Python 中实现多元线性回归模型
我们将使用 California Housing 数据集,其中包括收入中位数、平均房间和目标变量房价等特征。
1. 导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
2. 加载数据集
# Load the California Housing dataset
california_housing = fetch_california_housing()
# Assign the data (features) and target (house prices)
X = pd.DataFrame(california_housing.data, columns=california_housing.feature_names)
y = pd.Series(california_housing.target)
- 从 中获取 California Housing 数据集。
sklearn.datasets - 数据集包含存储在 中的特征(例如收入中位数、平均房间数),目标(房价)存储在 中。
Xy
3. 选择要可视化的特征
X = X[['MedInc', 'AveRooms']]
选择两个特征( 中位数收入 和 平均房间 )以将可视化简化为两个维度。MedIncAveRooms
4. Train-Test 拆分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
5. 初始化和训练模型
model = LinearRegression()
model.fit(X_train, y_train)
6. 做出预测
y_pred = model.predict(X_test)
7. 在 3D 中可视化最佳拟合线
fig = plt.figure(figsize=(10, 7))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(X_test['MedInc'], X_test['AveRooms'], y_test, color='blue', label='Actual Data')
x1_range = np.linspace(X_test['MedInc'].min(), X_test['MedInc'].max(), 100)
x2_range = np.linspace(X_test['AveRooms'].min(), X_test['AveRooms'].max(), 100)
x1, x2 = np.meshgrid(x1_range, x2_range)
z = model.predict(np.c_[x1.ravel(), x2.ravel()]).reshape(x1.shape)
ax.plot_surface(x1, x2, z, color='red', alpha=0.5, rstride=100, cstride=100)
ax.set_xlabel('Median Income')
ax.set_ylabel('Average Rooms')
ax.set_zlabel('House Price')
ax.set_title('Multiple Linear Regression Best Fit Line (3D)')
plt.show()
输出:

可视化多元线性回归
蓝色点表示基于要素(MedInc 和 AveRooms)的实际房价,红色表面表示多元线性回归模型预测的最佳拟合平面。此图显示了两个所选特征如何影响预测的房价。





















工程师必备
- 项目客服
- 培训客服
- 平台客服
TOP




